Data is the new currency. I once heard a leading autonomous vehicle manufacturer say, “..I envision a day when the data collected from the cameras on our vehicles is more valuable to our company than the vehicles themselves…” Because your organization’s data is so valuable, the need for robust, scalable, and highly available data storage systems should be of paramount concern. A striking statistic highlighting the impact of data availability comes from a recent report by DataNumen (May 2025). Their findings indicate that 85% of organizations experienced one or more data loss incidents in 2024. Even more alarming, the report notes that 93% of businesses that suffer prolonged data loss lasting more than 10 days go bankrupt within a year. This underscores the catastrophic, existential risk that storage systems delivering inadequate availability can negatively impact a business’s viability.
As we near the exabyte scale, coupled with the need for always-on applications, legacy storage architectures are increasingly proving inadequate for delivering high availability. This is where scalable, distributed block storage systems emerge, offering a compelling alternative that underpins modern cloud infrastructure, AI/ML workloads, and mission-critical applications. In this blog, I will explain the fundamental principles of distributed block storage, its benefits, and the key considerations for achieving high availability.
The Imperative of High Availability in Modern Data Infrastructure
High availability (HA) refers to an IT system’s ability to operate continuously without failure for a specified period. In the context of data storage, HA is critical. As you read in the introduction, downtime and data availability issues can result in significant financial losses, disruption to a business’s essential operations, or, in the case of e-commerce and financial services, reputational damage and even closure. For applications ranging from transactional databases to real-time analytics, in virtualized or containerized environments, uninterrupted access to data is the lifeblood of productivity.
Architecting storage systems for high availability has taken many forms over the years. Traditional systems, such as Direct-Attached Storage (DAS) or Storage Area Network (SAN), often rely on redundant hardware components, including RAID arrays and dual controllers, to mitigate single points of failure. While this approach is effective to a degree by offering component-level resilience or protection against failures within an array, the architecture is inherently limited in its scalability. Thus, the architecture is not suited for modern workloads at scale. In contrast, a distributed block storage architecture distributes data across multiple nodes that can span racks, data centers, or even regions, thereby distributing the risk and processing power to ensure resilience against a wider range of failures while offering high scalability and availability. An architecture better suited for modern workloads at scale.
What is Block Storage?
Before explaining a distributed architecture, it is essential to understand the concept of block storage. At the most basic level, block storage refers to the raw sectors or blocks on a physical disk drive (HDD or SSD). When an application accesses data at this level, it’s dealing directly with these blocks, which are the smallest addressable units of data. Block storage presents storage volumes to servers. Block storage divides data into fixed-sized units, or “blocks.” Each block has a unique address, enabling efficient data retrieval, modification, and management. Blocks can be stored across multiple physical or virtual drives. When a file is accessed or updated, the system retrieves or modifies only the relevant blocks, not the entire file. This makes block data storage efficient for random read/write operations and low-latency access. This granular control makes block storage ideal for performance-sensitive applications such as databases, which require high IOPS and predictable, consistent low latency, whether they are in virtualized or containerized environments.
To learn more about block storage and its use in data centers, read the blog: 4 Reasons Why Block Storage is Gaining Momentum in the Enterprise
Software-Defined Distributed Block Storage
Software-defined storage (SDS) technology is an approach to data storage architecture in which the software that manages storage-related tasks is decoupled from the physical storage hardware. SDS architecture enables storage provisioning, management, and optimization through software, abstracting the hardware. Software-defined storage is used primarily in data centers due to the need for storage consolidation, scalability, cost efficiency, flexibility, and centralized management. SDS helps modernize data center operations, making it a crucial component in meeting the evolving storage demands of today’s digital enterprises.
Distributed block storage can be software-defined for greater flexibility, automation, and cost savings. Organizations may find the ability to provision storage volumes on demand useful for managing storage overhead and operational costs. Data services such as compression, deduplication, and thin provisioning optimize storage utilization, further helping to reduce storage overhead costs.
To learn more about software-defined storage, read the blog: A Comprehensive Guide to Enterprise Software-Defined Storage Technology
What are the Benefits of Distributed Block Storage?
A distributed block storage system fundamentally changes how data is stored and accessed. Block storage can be exposed and utilized by servers in various architectural configurations, including DAS and SAN. But instead of residing on a single, centralized storage array, such as Dell’s PowerStore, data blocks are spread across multiple independent storage nodes, connected via a high-speed network.
The distributed block storage architecture has several significant advantages:
- Highly Scalable: As data volumes grow, new storage nodes can be added to the cluster, seamlessly expanding capacity and performance without requiring costly and disruptive forklift upgrades. This horizontal scaling capability is a hallmark of modern cloud infrastructure.
- No Single Point of Failure: Data is replicated across multiple nodes within the distributed system, ensuring redundancy, superior HA, and fault tolerance. If one node fails, the system automatically reroutes requests to healthy replicas, ensuring continuous data accessibility. This inherent redundancy minimizes downtime and protects against data loss, even in the event of hardware failures, network partitions, or entire node outages.
- Improved Performance: By distributing data across multiple nodes and leveraging parallel processing, distributed block storage can achieve significantly higher aggregate IOPS and throughput compared to single storage arrays. Workloads are balanced across the cluster, preventing hot spots and optimizing resource utilization.
- No Vendor Lock-In: Distributed block storage solutions can leverage commodity hardware, reducing the capital expenditure and vendor lock-in associated with proprietary storage solutions.
- Cost-Efficiency: The ability to scale incrementally further optimizes costs, as organizations only add capacity as needed.
- Improves Disaster Recovery Strategies: Many distributed block storage solutions support deploying nodes across different physical locations or availability zones, further enhancing disaster recovery capabilities and providing data proximity for geographically dispersed users.
Distributed Block Storage: Key Components and Design Principles
If you are building a cloud from the ground up, using Ceph storage or Lightbits software-defined storage, and want the distributed storage architecture, then there are several critical components and design principles to be mindful of:
- Storage Nodes: These are the individual servers that contribute storage capacity and processing power to the cluster. Each node typically contains local storage devices (e.g. NVMe storage) and network interfaces.
- Network Fabric: A high-speed, low-latency network is crucial for efficient and rapid data R/W operations between storage nodes and client applications. NVMe® over TCP (NVMe/TCP) has revolutionized this aspect, enabling local flash-level performance over standard Ethernet networks and eliminating the need for expensive Fibre Channel SANs.
- Metadata Management: The system requires a mechanism to track the storage locations of data blocks across the distributed cluster. This metadata management layer is crucial for efficient data retrieval and consistency. Some systems utilize a centralized metadata server, while others employ a distributed metadata approach for enhanced resilience.
- Data Replication and Consistency: To ensure HA and data durability, data blocks are replicated across multiple nodes. Various replication strategies exist, such as synchronous (writes confirmed by all replicas before completion) or asynchronous (writes acknowledged locally, replicated later). The choice of replication strategy impacts consistency guarantees (e.g., strong consistency vs. eventual consistency) and performance.
- Load Balancing and Data Distribution: The system must intelligently distribute data blocks and I/O requests across the cluster to optimize performance and prevent bottlenecks. This often involves dynamic rebalancing as nodes are added or removed.
- Fault Detection and Self-Healing: A reliable distributed block storage system should continuously monitor its health. Upon detecting a failure, it should automatically initiate self-healing mechanisms, such as re-replicating lost data blocks from healthy replicas to new nodes, to restore the desired level of redundancy.
What is Open Source Distributed Block Storage?
While open source distributed block storage offers a powerful and cost-effective foundation, organizations must be prepared for the significant investment in expertise, operational tooling, and ongoing management required to successfully deploy and maintain these systems in production. For some, the total cost of ownership is higher than that of a commercial solution if internal expertise is lacking. A notable example is Ceph storage.
Organizations from a wide range of industries are building their own on-premises, private clouds with software-defined storage emerging as the preferred solution. Open-source Ceph Storage is frequently considered. Ceph is a highly versatile, open-source distributed storage platform that offers block, object, and file storage capabilities. But where high performance at scale is required, Ceph Storage often shows significant limitations. Tests have shown that Lightbits block storage outperforms Ceph 16X; learn more about Lightbits comparisons to Ceph. When evaluating Ceph’s suitability for your production environment, carefully consider factors such as community support, enterprise-grade features, and the availability of professional services.
For a comparison of Lightbits to Ceph Storage, download the whitepaper.
Lightbits: a Distributed Block Storage Leader
Lightbits offers a software-defined, disaggregated block storage solution purpose-built for demanding, always-on, mission-critical workloads at scale, such as AI/ML workloads, and high-performance databases. In the realm of distributed block storage and high availability, Lightbits is a leading force.
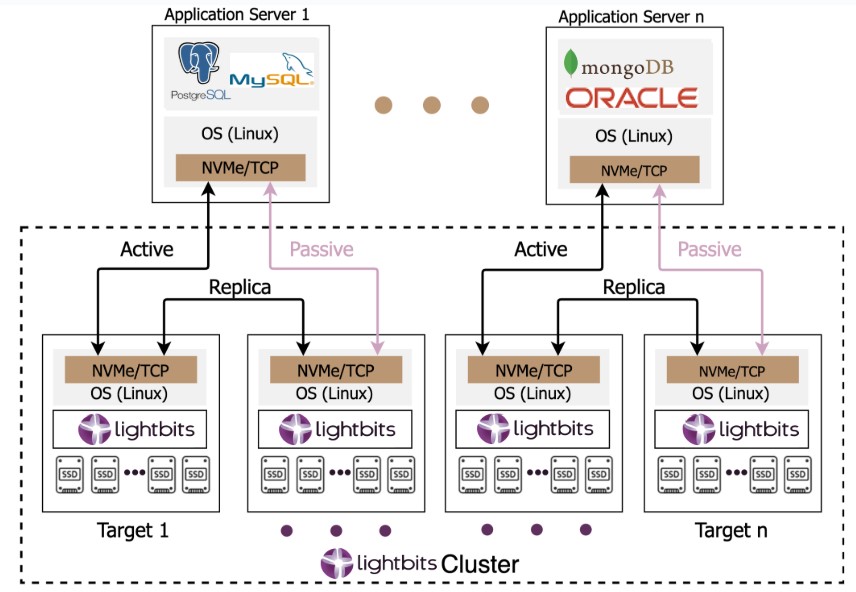
Lightbits NVMe/TCP scale-out, highly available distributed block storage
Lightbits Labs invented NVMe/TCP, which is natively designed into the software to deliver ultra-low latency and high-performance block storage over standard Ethernet networks. This allows applications to access remote storage with performance comparable to local NVMe SSDs, eliminating the need for expensive, proprietary Fibre Channel SANs, simplifying infrastructure, and reducing costs.
Other key benefits Lightbits’ distributed block storage include:
- Disaggregated Architecture: Lightbits separates compute and storage, allowing them to scale independently. This provides greater flexibility and resource utilization efficiency.
- Software-Defined: Runs on commodity servers and integrates seamlessly with popular orchestration platforms like Kubernetes, OpenShift, and OpenStack.
- Enterprise-Ready Data Services: Offers multi-zone replication and self-healing capabilities to ensure enterprise-grade resiliency and HA. Data is protected from single instance failures through automatic re-replication and recovery mechanisms. Features such as compression, thin provisioning, snapshots, and clones are included in the software license.
- Unmatched Price/Performance Value: NVMe/TCP and Intelligent Flash Management optimize storage resource utilization, leverage standard hardware, and accelerate application performance without requiring additional cores or nodes.
For organizations seeking to modernize their infrastructure and support data-intensive workloads, Lightbits’ approach to distributed block storage provides a compelling combination of implementation flexibility, performance and cost efficiency. Its ability to provide consistent low latency and high throughput makes it an ideal block storage service for mission-critical applications that demand predictable performance at scale.
Conclusion
If an organization is to thrive, understanding the IT system architecture that offers the greatest data protection and availability is paramount. Don’t wait for a catastrophe to realize your legacy storage systems don’t provide the HA you need to survive a disaster. Don’t be a statistic.
Distributed block storage is the architecture of choice for modern data centers, offering more than high availability (HA), but also the ability to scale on demand. By understanding the core principles of distributed block storage, IT professionals can make informed decisions on how to achieve HA by using modern block storage solutions, such as software from Lightbits.

